Функции для работы со строками
Создадим тестовую таблицу.
create table articles(
title varchar2(50) not null,
author varchar2(50) not null,
msg varchar2(300) not null,
publish_date date not null
);
comment on table articles is 'Твиты';
comment on column articles.title is 'Заголовок';
comment on column articles.author is 'Автор';
comment on column articles.msg is 'Сообщение';
insert into articles values ('Новый фотоаппарат!', 'johndoe',
'Сегодня купил себе новый фотоаппарат. Надеюсь, у меня будут получаться отличные фотографии!', sysdate);
insert into articles values ('Насобирал денег', 'johndoe',
'Целый год я шел к этой цели, и вот наконец-то у меня все получилось, и заветная сумма собрана!', sysdate - 1);
insert into articles values ('Задался целью', 'johndoe',
'Итак, я задался целью купить себе фотоаппарат. Для начала нужно насобирать денег на него.', sysdate - 2);
insert into articles values ('Сходил в ресторан!', 'user003',
'Пришел из ресторана. Еда была просто восхитительна!', sysdate - 3);
insert into articles values ('Съездили в отпуск!', 'artem69',
'Наконец-то выбрались с женой и детьми в отпуск, было замечательно!', sysdate - 4);Таблица articles представляет собой место хранения сообщений пользователей, что-то вроде twitter.
UPPER, LOWER
Данные функции уже описывались раньше.
UPPER: приводит строку к верхнему региструLOWER: приводит строку к нижнему регистру
Рекомендуется использовать одну из этих функций, если нужно сравнить две строки между собой без учета регистра символов.
Конкатенация строк
Конкатенация - это "склейка" строк. Т.е., если у нас есть 2 строки - "Новый", "фотоаппарат", то результатом конкатенации будет строка "Новый фотоаппарат".
Для склейки строк в Oracle используется оператор ||.
select 'Автор:' || art.author frmt_author,
'Заголовок:"' || art.title || '"' frmt_title
from articles art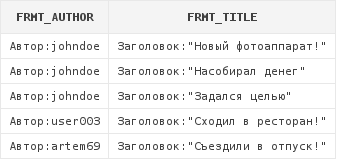
Поиск подстроки
Для того, чтобы найти вхождение одной строки в другую, используется функция INSTR. Она возвращает позицию вхождения одной строки в другую. Если вхождения не обнаружено, то в качестве результата будет возвращён 0.
Следующий запрос возвращает позицию, начиная с которой в заголовках записей пользователей встречается символ восклицательного знака:
select a.title,
instr(a.title, '!') pos
from articles a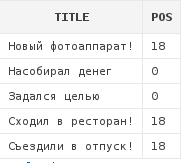
Как видно, для тех заголовков, которые не содержат восклицательный знак, функция INSTR вернула 0.
В функции INSTR можно задавать позицию, начиная с которой следует производить поиск вхождения:
select a.title,
instr(a.title, 'о', 3) pos
from articles a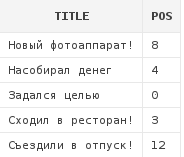
Данный запрос вернет позицию буквы о в заголовках записей, но поиск будет производить лишь начиная с 3-го символа заголовка.
Так, в строке "Новый фотоаппарат" мы получили результат 8, хотя буква о есть и раньше - на второй позиции.
В качестве стартовой позиции поиска можно указывать отрицательное число. В этом случае функция отсчитает от конца строки указанное количество символов и будет производить поиск начиная от этой позиции и заканчивая началом строки:
select a.title,
instr(a.title, 'а', -4) pos
from articles a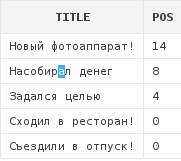
Также можно указать, какое по счету совпадение нужно искать(4-ый параметр в функции INSTR):
select a.title,
instr(a.title, 'о', 1, 2) pos
from articles a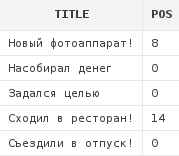
Подобие строк. Like
Для рассмотрения этой темы будем использовать данные из части про сортировку.
Предположим, нам понадобилось посмотреть, какие чаи есть у нас в меню. В данном примере единственный способ, которым мы можем определить, что блюдо является чаем - это проверить, содержится ли слово чай в наименовании.
Но оператор сравнения здесь не подойдет, так как он вернет лишь те строки, которые будут полностью совпадать со строкой Чай.
Перед рассмотрением примера добавим в таблицу меню немного чайных блюд:
insert into dishes(name, price, rating) values ('Зеленый чай', 1, 100);
insert into dishes(name, price, rating) values ('Чай%', 2, 100);
insert into dishes(name, price, rating) values ('Чай+', 1, 200);
insert into dishes(name, price, rating) values ('Чай!', 1, 666);Гениальные маркетологи решили, что будут добавлять по одному символу в конце слова чай для обозначения его крепости - "чай%" - совсем слабенький, "чай+" взбодрит с утра, а с "чаем!" можно забыть про сон на ближайшие сутки. Не будем задумываться, почему именно так, а просто примем это как есть.
Итак, первый пример использования LIKE:
select d.*
from dishes d
where d.name like 'Чай%'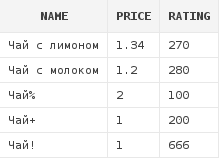
Как видно, были получены все блюда, наименования которых начиналось с последовательности символов, составляющей слово Чай. Символ "%" в условии LIKE соответствует любой последовательности символов. Т.е. предыдущий запрос можно было читать так: "Получить все блюда, первые символы наименований которых составляют слово Чай, а после этих символов следует последовательность из любых символов в любом количестве, мне не важно". Кстати, в результат не попал зеленый чай - первые 3 символа наименования у него равны "Зел", но никак не "Чай".
Если не указывать символ "%", то запрос не вернет никаких данных:
select d.*
from dishes d
where d.name like 'Чай'
При задании шаблонов в LIKE можно использовать следующие символы соответствия:
- "%"(знак процента). Ему соответствует 0 или больше символов в значении.
- "_"(нижнее подчеркивание). Ему соответствует ровно один символ в значении.
Получим все чаи, названия которых придумали маркетологи(а это любой 1 символ после слова "чай"):
select d.*
from dishes d
where d.name like ('Чай_')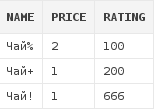
Также, как и при обычном сравнении, учитывается регистр строк. Следующий запрос не вернет никаких данных, т.к. нет блюд, начинающихся со строки "чай", есть только блюда, начинающиеся на "Чай"(первая буква заглавная):
select d.*
from dishes d
where d.name like ('чай%')
Получим только зеленый чай:
select d.*
from dishes d
where d.name like ('%чай')
Здесь символ процента был перемещен перед словом "чай", что означает: "Любая последовательность символов(или их отсутствие), заканчивающаяся словом чай".
А для того, чтобы получить список всех блюд, в наименовании которых содержится слово "чай", можно написать следующий запрос:
select d.*
from dishes d
where upper(d.name) like upper('%чай%')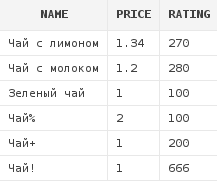
Выражение ESCAPE в LIKE
Перед рассмотрением выражения опять добавим немного данных в таблицу dishes:
insert into dishes values ('Кофе(0.4% кофеина)', 30, 20);
insert into dishes values ('Кофе(0.3% кофеина)', 30, 20);
insert into dishes values ('Кофе(0.1% кофеина)', 30, 20);
insert into dishes values ('Кофе(без кофеина)', 30, 20);Перед нами стоит задача: получить список кофейных блюд, содержащих кофеин.
Можно выделить некоторый список признаков, по которым мы сможем определить, что кофе с кофеином:
- Наименование начинается со слова "Кофе"
- Если кофе с кофеином, то в скобках указывается его процентное содержание в виде "n% кофеина", где n - некоторое число.
На основании этих заключений можно написать следующий запрос:
select d.*
from dishes d
where d.name like ('Кофе%кофеина')
В чем проблема, должно быть понятно - в том, что символ "%" в условии LIKE обозначает совпадение с 0 или больше любых символов.
Для того, чтобы учитывать непосредственно символ "%" в строке, условие LIKE немного видоизменяется:
select d.*
from dishes d
where d.name like ('Кофе%\% кофеина%') escape '\'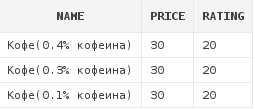
Здесь после ключевого слова escape мы указываем символ, который будет экранирующим, т.е. если перед символами% будет стоять символ \, то он будет рассматриваться как совпадение с одним символом %, а не как совпадение 0 и больше любых символов.
Приведение к верхнему регистру. INITCAP
Функция INITCAP делает первую букву каждого слова заглавной, оставляя остальную часть слова в нижнем регистре.
select initcap(art.author)
from articles art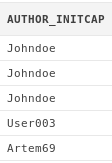
select initcap(art.msg) msg_initcap
from articles art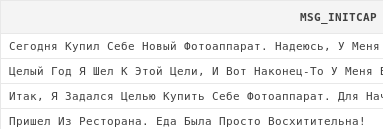
INFO
Если строка состоит из нескольких слов, то в каждом из этих слов первая буква будет заглавной, а остальные - прописными.
Замена подстроки. REPLACE
Для замены подстроки в строке используется функция REPLACE. Данная функция принимает 3 параметра, из них последний - не обязательный:
replace(исходная_строка, что_меняем, на_что_меняем)В случае, если не указать, на какую строку производить замену, то совпадения будут просто уделены из исходной строки.
Например, получим все "твиты" пользователя johndoe, но в заголовке поста заменим слово "фотоаппарат" заменим на слово "мыльница":
select replace(a.title, 'фотоаппарат', 'мыльница') new_title,
a.msg
from articles a
where a.author = 'johndoe'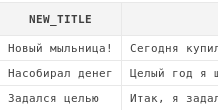
Удаление пробелов. TRIM
Есть 3 основных функции для удаления "лишних" пробелов из строки:
trim- удалить пробелы вначале и в конце строкиltrim- удалить пробелы вначале строки (слева)rtrim- удалить пробелы в конце строки (справа)
select trim(' John Doe ') from dual;
select rtrim(' John Doe ') from dual;
select ltrim(' John Doe ') from dual;
-- То же самое, что и trim
select ltrim(rtrim(' John Doe ')) from dual;LPAD, RPAD
Эти функции используются, чтобы дополнить строку какими-либо символами до определенной длины.
LPAD (left padding) используется для дополнения строки символами слева, а RPAD (right padding) - для дополнения справа.
select lpad('1', 5, '0') n1,
lpad('10', 5, '0') n2,
lpad('some_str', 10) n2_1,
rpad('38', 5, '0') n3,
rpad('3', 5, '0') n4
from dual
Первый параметр в этой функции - строка, которую нужно дополнить, второй
- длина строки, которую мы хотим получить, а третий - символы, которыми будем дополнять строку. Третий параметр не обязателен, и если его не указывать, то строка будет дополняться пробелами, как в колонке
n2_1.