Аналитические функции
Аналитические функции - очень мощный инструмент в SQL. Со слов Тома Кайта, можно написать отдельную книгу по аналитическим функциям, настолько они полезны.
Аналитические функции - это те же агрегирующие функции, но их главная особенность в том, что они работают без необходимости группировки строк.
Аналитические функции выполняются последними в запросе, поэтому они могут быть использованы только в SELECT части запроса, либо в ORDER BY.
Для примера возьмем данные, которые мы использовали при разборе агрегирующих функций:
alter table employees
add (exp number);
merge into employees emp
using (select level lvl, rownum * 10 exp
from dual
connect by level <= 4) val
on (emp.id = val.lvl)
when matched then
update
set emp.exp = val.exp;Посмотрим, какие данные теперь хранятся в таблице:
select *
from employees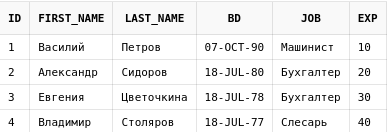
Теперь напишем запрос, который бы возвращал максимальный стаж среди всех сотрудников отдельной колонкой. Для этого можно использовать подзапрос:
select id,
first_name,
last_name,
(select max(exp) from employees) max_exp
from employees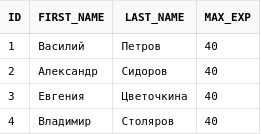
Усложним задачу: напишем запрос, который будет возвращать отдельной колонкой максимальный стаж на должности каждого сотрудника. Для этого также можно использовать подзапрос, только уже коррелированный:
select emp.first_name,
emp.last_name,
emp.job,
(select max(exp) from employees where job = emp.job) max_exp
from employees emp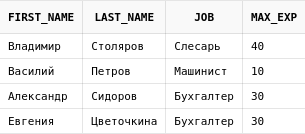
Теперь решим эти же задачи при помощи аналитический функций:
select emp.first_name,
emp.last_name,
emp.job,
max(exp) over () max_exp
from employees empselect emp.first_name,
emp.last_name,
emp.job,
max(exp) over (partition by job) max_exp
from employees empАналитические функции позволяют использовать агрегирующие функции без подзапросов, что уменьшает размер запроса( примеры, когда использование подзапроса усложняет чтение запроса, будут немного дальше).
Помимо этого, вот еще два примера запросов с аналитическими функциями.
select id,
first_name,
last_name,
job,
bd,
exp,
max(exp) over (order by first_name) max_exp_asc,
max(exp) over (order by first_name desc) max_exp_desc
from employees emp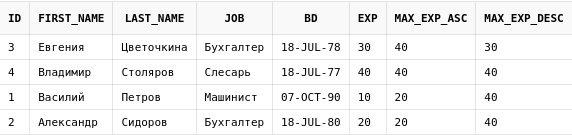
Две колонки, max_exp_asc и max_exp_desc, считают максимальный стаж среди сотрудников в порядке возрастания и убывания их имен соответственно.
С простыми примерами аналитических функций мы познакомились, теперь разберемся,как они работают.
Когда агрегирующая функция становится аналитической
В первом примере агрегирующая функция max превратилась в аналитическую после добавления к ней части over(). В итоге, было найдено максимальное значение колонки exp среди всего набора данных, и это значение было добавлено к каждой строке выборки, без группировки.
Подсчет результатов по группам. Partition by
Для того, чтобы результаты считались по определенным группам, нужно использовать конструкцию partition by, в которой нужно указать колонки, по которым будет производиться вычисление.
select emp.first_name,
emp.last_name,
emp.job,
max(exp) over (partition by job) max_exp
from employees empВ данном примере, который уже приводился раньше, максимальный стаж вычисляется в отдельности для каждой из профессий, и затем добавляется к каждой строке.
Посчитаем количество сотрудников по должностям и выведем отдельной колонкой:
select emp.first_name,
emp.last_name,
emp.job,
count(*) over (partition by job) job_cnt
from employees emp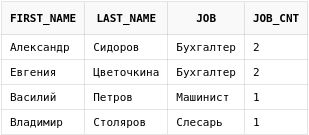
Результаты можно считать по нескольким группам. Выведем напротив каждого сотрудника общее число сотрудников, родившихся в том же месяце(колонка mnth_cnt) и количество сотрудников, родившихся в том же месяце и занимающих такую же должность:
select emp.id,
emp.first_name,
emp.last_name,
emp.job,
emp.bd,
count(*) over(
partition by extract(month from emp.bd)
) mnth_cnt,
count(*) over (
partition by extract(month from emp.bd), job
) mnth_cnt
from employees emp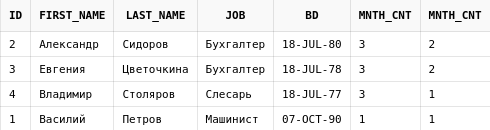
Всего есть три сотрудника, которые родились в одном и том же месяце - июле. Поэтому в колонке mnth_cnt отображается число 3. В то же время, есть лишь два сотрудника, которые родились в одном и том же месяце, и при этом занимают одну и ту же должность - это сотрудники с id равными 2 и 3.
Порядок вычисления. Order by
В аналитических функциях можно указывать порядок, в котором они будут работать с итоговым набором данных. Для этого используется конструкция order by.
Пронумеруем строки в нашей таблице в порядке возрастания и убывания дней рождения сотрудников.
select emp.id,
emp.first_name,
emp.last_name,
emp.job,
emp.bd,
row_number() over (order by bd) bd_asc,
row_number() over (order by bd desc) bd_desc
from employees emp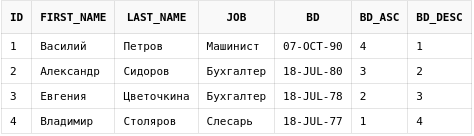
Функция row_number возможно является одной из самых часто используемых аналитических функций. Она возвращает номер строки в итоговой выборке. До ее появления в Oracle подобного функционала можно было достичь лишь при использовании подзапросов и псевдостолбца ROWNUM.
Аналитические функции могут работать не только по группам или в определенном порядке, но и в определенном порядке в пределах заданной группы:
select emp.id,
emp.first_name,
emp.last_name,
emp.job,
emp.bd,
row_number() over (
partition by job order by bd
) bd_asc,
row_number() over (
partition by job order by bd desc
) bd_desc
from employees emp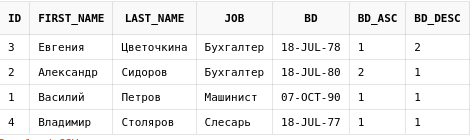
Здесь нумерация производится отдельно для каждой группы. У двух сотрудников с одинаковой должностью нумерация была проставлена в порядке их дней рождения.
Диапазон работы аналитических функций
Аналитические функции всегда, явно или неявно, применяются к определенному набору строк, называемому окном аналитической функции.
Не во всех аналитических функциях можно указывать окно. Среди самых часто используемых функций, для которых можно указывать окно, находятся MIN, MAX, SUM, AVG, COUNT, LAST_VALUE, FIRST_VALUE и другие.
Чтобы примеры были немного более практичными, создадим еще одну таблицу, в которой будем хранить данные о начисленных зарплатах сотрудникам по месяцам:
create table emp_salary(
emp_id number not null,
sal_date date not null,
sal_value number not null,
-- Начисления в данной таблице должны быть
-- "сбитыми" по месяцам, и чтобы в данных не
-- возникло ошибки, создаем уникальный ключ на
-- поля с id сотрудника и месяцем начисления
constraint emp_salary_uk unique(emp_id, sal_date)
);
comment on table emp_salary is
'Зачисленные средства по месяцам';
comment on column emp_salary.emp_id is
'id сотрудника';
comment on column emp_salary.sal_date is
'Месяц начисления';
comment on column emp_salary.sal_value is
'Начисленные средства';
insert into emp_salary(emp_id, sal_date, sal_value)
values(1, to_date('01.01.2020', 'dd.mm.yyyy'), 1000);
insert into emp_salary(emp_id, sal_date, sal_value)
values(1, to_date('01.02.2020', 'dd.mm.yyyy'), 1320);
insert into emp_salary(emp_id, sal_date, sal_value)
values(1, to_date('01.03.2020', 'dd.mm.yyyy'), 850);
insert into emp_salary(emp_id, sal_date, sal_value)
values(2, to_date('01.01.2020', 'dd.mm.yyyy'), 1000);
insert into emp_salary(emp_id, sal_date, sal_value)
values(2, to_date('01.02.2020', 'dd.mm.yyyy'), 800);
insert into emp_salary(emp_id, sal_date, sal_value)
values(2, to_date('01.03.2020', 'dd.mm.yyyy'), 1200);
insert into emp_salary(emp_id, sal_date, sal_value)
values(3, to_date('01.01.2020', 'dd.mm.yyyy'), 1030);
insert into emp_salary(emp_id, sal_date, sal_value)
values(4, to_date('01.01.2020', 'dd.mm.yyyy'), 3700);Общие данные выглядят следующим образом:
select e.first_name,
e.last_name,
e.job,
es.sal_date,
es.sal_value
from emp_salary es
join employees e on e.id = es.emp_id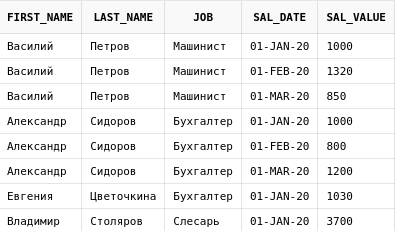
Теперь добавим колонку к выборке, которая будет показывать, как изменялась минимальная заработная плата сотрудников с течением времени.
select e.first_name,
e.last_name,
e.job,
es.sal_date,
es.sal_value,
min(es.sal_value) over (
order by sal_date
rows between unbounded preceding and
current row
) min
from emp_salary es
join employees e on e.id = es.emp_id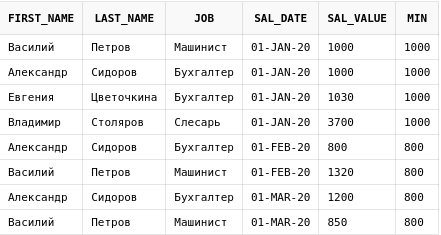
Сейчас может показаться, что результат, который получился в запросе такой же, как если бы мы и не задавали размер окна. Действительно, для текущих данных запрос без добавления лишних ключевых слов выдает такой же результат:
select e.first_name,
e.last_name,
e.job,
es.sal_date,
es.sal_value,
sum(es.sal_value) over (order by sal_date) min
from emp_salary es
join employees e on e.id = es.emp_id
Чуть позже станет понятно, что это 2 совершенно разных запроса, а пока разберем подробнее различные варианты указания окна в аналитических функциях.
Строки и значения
Строки, которые определяют окно работы аналитической функции, можно указывать физически, т.е. сказать БД: "Для текущей строки в выборке аналитическая функция должна обработать две строки перед ней и три строки после нее"; или: "Для текущей строки в выборке аналитическая функция должна обработать все строки начиная с текущей и заканчивая всеми последующими строками".
Вторым возможным способом определения окна является определение не по физическому расположению строки в выборке, а по значениям, которые строки в себе содержат. Мысленно это можно произнести: "Для текущей строки в выборке аналитическая функция должна обработать те строки, в которых значение колонки А будет больше, чем значение в колонке А текущей строки"; или: "Для текущей строки в выборке аналитическая функция должна обработать те строки, в которых значение колонки А будет в пределах от 10 до 20 включительно".
В первом случае, при указании физических строк, используется ключевое слово ROWS, во втором случае, при указании строк по их значениям, используется ключевое слово RANGE.
Смещения при определении окна
Итак, при указании окна мы должны задать его верхнюю и нижнюю границу.
В общем виде указание границы выглядит следующим образом:
(range или rows) between "Верхняя граница" and "Нижняя граница"
Теперь рассмотрим варианты для этих границ:
UNBOUNDED PRECEDING- указывает, что окно начинается с первой строки в разделе. Может быть указано только для верхней границы, в качестве нижней границы использовать нельзя.UNBOUNDED FOLLOWING- указывает, что окно заканчивается на последней строке в разделе. Может быть указано только для нижней границы.CURRENT ROW- обозначает текущую строку или значение. Может быть использовано как для нижней границы, так и для верхней.PRECEDING- значение в строке или физическая строка, которая предшествует текущей строке наFOLLOWING- значение в строке или физическая строка, которая находится впереди текущей строки на
Следует помнить, что если окно задается с использованием ROWS, т.е. указываются строки, то и границы окна будут задаваться в строках, и наоборот, если используется , то границы окна будут учитываться по значениям в строках.
Если окно не указывается, то по-умолчанию оно имеет вид RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
Теперь посмотрим на один из предыдущих запросов:
select e.first_name,
e.last_name,
e.job,
es.sal_date,
es.sal_value,
min(es.sal_value) over (
order by sal_date
rows between unbounded preceding
and current row
) min
from emp_salary es
join employees e on e.id = es.emp_idРассмотрим, как будет работать аналитическая функция.
PARTITION BY не указан, значит результаты будут "сплошные" и не будут разбиваться по группам. Обрабатываться строки будут в порядке возрастания даты в колонке sal_date, а диапазон строк, для которых будет вычисляться функция, задается первой строкой во всем наборе данных и заканчивается текущей строкой.
Теперь должна быть понятна разница между данным запросом и запросом без указания окна, о которой говорилось в начале раздела - по-умолчанию окно задается по значению, а мы установили размер окна со смещениями в строках.
Еще один важный момент: значения в колонке sal_date не являются уникальными. Это означает, что результат будет недетерминированным, т.е. может отличаться от запуска к запуску, т.к. порядок следования строк в выборке может измениться.
Чтобы избавиться от такого эффекта, можно добавить еще одну колонку в конструкцию order by, чтобы сделать порядок следования строк уникальным и не меняющимся. В данном случае мы можем дополнительно сортировать данные по id сотрудника:
min(es.sal_value) over (
order by sal_date, id
rows between unbounded preceding
and current row
) minВ общем, когда несколько колонок имеют одинаковые значения, аналитические функции работают по определенным правилам:
- Функции
CUME_DIST,DENSE_RANK,NTILE,PERCENT_RANKиRANKвозвращают одинаковый результат для всех строк - Функция
ROW_NUMBERприсвоит каждой строке уникальное значение. Порядок присваивания будет зависеть от порядка обработки строк БД, который мы не можем предугадать - Все остальные функции будут работать по-разному в зависимости от спецификации окна. Если окно задавалось при помощи
RANGE, то функция вернет одинаковое значение для всех строк. Если использовалось ключевое словоROWS, то результат нельзя будет предугадать - он опять же будет зависеть от порядка обработки строк базой данных, который может отличаться для одного и того же набора данных от запуска к запуску.
Размеры окна можно задавать в виде смещений:
select e.first_name,
e.last_name,
e.job,
es.sal_date,
es.sal_value,
round(
avg(es.sal_value)over (
order by sal_date, id
rows between 2 preceding and current row
),
2) avg_sal
from emp_salary es
join employees e on e.id = es.emp_id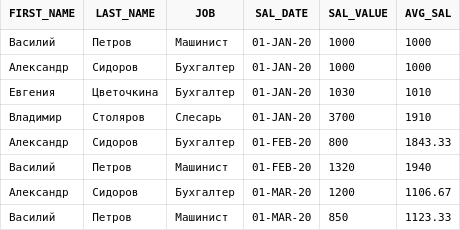
Здесь в колонке avg_sal считается средняя заработная плата по трем строкам - двум предшествующим и текущей. Порядок следования, как мы помним, задается при помощи ORDER BY, поэтому две предшествующие строки
- это строки, у которых значение в колонках
sal_dateбудет меньше либо равным значению в текущей строке.
Значение функции округляется до двух знаков после запятой при помощи функции round. Аналитическая функция берется в скобки полностью, начиная от имени функции и заканчивая определением окна. К значениям, полученным при помощи аналитических функций можно применять другие функции или операторы - например, можно было бы добавить 100 к среднему значению:
avg(es.sal_value)over (
order by sal_date
rows between 2 preceding and current row
) + 100 avg_salИли даже получить разность между значениями двух аналитических функций:
max(es.sal_value)
over (
order by sal_date
range between 1 preceding and current row
) -
min(es.sal_value)
over (
order by sal_date
rows between 1 preceding and current row
)В следующем примере смещение задается не в строках, а в диапазоне значений, которые содержит колонка sal_value:
select e.first_name,
e.last_name,
e.job,
es.sal_date,
es.sal_value,
sum(es.sal_value) over (
order by sal_value
range between 1000 preceding and current row
) max_sal
from emp_salary es
join employees e on e.id = es.emp_id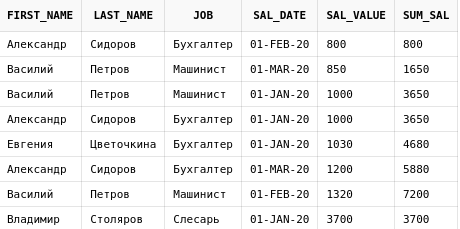
Т.к. использовался RANGE, то сумма рассчитывается для всех строк, значение которых находится в диапазоне от 1000 до значения в текущей строке.
Еще раз, следует обратить внимание, что строки, которые находятся после текущей, также обрабатываются функцией, если значение колонки sal_value входит в заданный диапазон. Это можно видеть на изображении выше, в строках, где значение sal_value равно 1000 - для первой строки в сумму посчиталось и значение следующей.
Следующий пример считает сумму по четырем строкам - в окно входят 2 предшествующие строки, текущая строка и одна строка, следующая за текущей:
select e.first_name,
e.last_name,
e.job,
es.sal_date,
es.sal_value,
sum(es.sal_value) over (
order by sal_value
rows between 2 preceding and 1 following
) sum_sal
from emp_salary es
join employees e on e.id = es.emp_id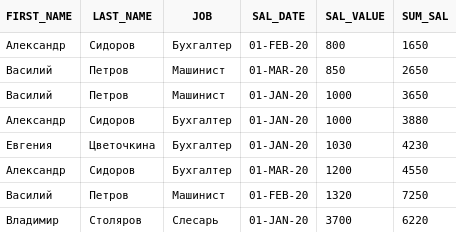
Т.к. окно задавалось с использованием ROWS, сумма считается именно по строкам, а не по их значениям. Для первой строки в сумму были взяты данные из нее самой и следующей, т.к. предыдущих строк у нее нет. Для второй строки была лишь одна предыдущая строка, а у последней не было следующей.
Ограничения на ORDER BY
ORDER BY в аналитических функциях может использоваться только с одной колонкой, за исплючением случаев, когда используется RANGE и окно задается одним из следующих способов:
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROWRANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWINGRANGE BETWEEN CURRENT ROW AND CURRENT ROWRANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING